Chicago Parking Ticket Visualization
Intro
Hi there! In this post, I want to show off a fun little web app I made for visualizing parking tickets in Chicago, but because I've spent so much time on the overall project, I figured I'd share the story that got me to this point. In many ways, this work is the foundation for my interest in public records and transparency, so it has a very special place in my heart.
If you're here just to play around with a cool app, click here. Otherwise, I hope you enjoy this post and find it interesting. Also - please don't hesitate to share harsh criticism or suggestions. Enjoy!
Project Beginnings
Back in 2014, while on vacation, my car was towed for allegedly being in a construction zone. The cost to get the car out was quoted at around $700 through tow fees and storage fees that increase each day by $35. That's obviously a lot of money, so the night I noticed the car was towed, I began looking for ways to get the ticket thrown out in court. After some digging, I found a dataset on data.cityofchicago.org which details every street closure, including closures for construction. As luck would have it, the address that my car was towed at had zero open construction permits, which seemed like a good reason to throw out the fines. The next day I confirmed the lack of permits by calling Chicago's permit office - they mentioned they only thing found was a canceled construction permit by Comed. That same day, I scheduled a court date for the following day.
When I arrived in the court room, I was immediately pulled aside by a city employee and was told that my case was being thrown out. They explained that the ticket itself "didn't have enough information", but besides that I wasn't told much! The judge then signed a form that allowed the release of my car at zero cost.
At this point, I'd imagine most folk would just walk away with some frustration, but would be overall happy and move on. For whatever reason, though, I'm too stubborn for that - I couldn't get over the fact that Chicago didn't just spend five minutes checking the ticket before I appeared in court. And what bothered me more was that there isn't some sort of sorts automated check. Surely Chicago has some process in place within its $200 million ticketing system to make sure it's not giving out invalid tickets... Spoiler: it doesn't.
The more I thought about it, the more I started wondering why Chicago's court system only favors those who have the time and resources to go to court and started wondering if it was possible to automate these checks myself using historical data. The hunch started based on what I'd seen from the recent "Open Gov" movement in to start making data open to the public by default.
When I first started, I mostly just worked with some already publicly available datasets previously released by several news organizations. WBEZ in particular released a fairly large dataset of towing data that, while it was a compelling dataset, it unfortunately ultimately wasn't useful for my little project. So instead, I started working on a similar goal to programatically find invalid tickets in Chicago. That work and its research led to my very first FOIA request, where after some trial and error, received the records for 14m parking tickets.
Trial Development and Trial Geocoding
With the data at hand, I started throwing many, many unix one liners and gnuplot at the problem. This method worked well enough for small one-off checks, but for anything else, it's a complete mess of sed and awk statements. After unix-by-default I moved on to Python, where I made a small batch of surprisingly powerful, but scraggly scripts. One script, for example, would check to see whether a residential parking permit ticket was valid by comparing a ticket's address against a set of streets and its ranges found on data.cityofchicago.org. The script ended up finding a lot of residential permit tickets given outside of the sign's listed boundaries. Sadly though, none of the findings were relevant, since a ticket is given based on the physical location of the sign, not what the sign's location data represents. These sorts or problems ended up putting a halt to these sorts of scripts.
With the next development iteration, I switched to visualizing parking tickets, where I essentially continued until today. Problem was, the original data had no lat/lng and had to be geocoded..
So, back when I first started doing this, there weren't that many geocoding services that were reasonably priced. Google was certainly possible, but its licensing and usage limits made Google a total no-go. The other two options I found were from Equifax (expensive) and the US Post Office (also expensive). So I went down a several hundred hour rabbit hole of attempting to geocode all addresses myself - entirely under the philosophy that all tickets had a story to tell, and anything lower than 90% geocoding was inexecusable.
The first attempt at geocoding was decent, but only matched about 30% of tickets. It worked by tokenizing addresses using a wonderful python library called usaddress, then comparing the "string distance" of a street address against a known set of address already paired with lat/long. It got me to a point where I could make my first map visualization using some simple plotting:
Jupyter Notebook
Still, with only 30% geocoded, I felt that I could do better through many different methods that continued to use string distance - some implementations much fancier than others. Other methods, ahem, used lots of sed and vim, which I'm still not proud of. There were some attempts where I got close to 90% of addresses geocoded, though I ended up throwing each one out in fear that the lack of validation would bite me in the future. Spoiler: it did.
Eventually, my life was made much easier thanks to the folks at SmartyStreets, who set me up an account with unlimited geocoding requests. By itself, SmartyStreets was able to geocode around 50% of the addresses, but when combined with some of my string-distance autocorrection, that number shot up to 70%. It wasn't perfect, but it was "good enough" to move on, and didn't really require me to trust my own set corrections and the anxiety that comes with that.
Another New Dataset
Fast forward about six months - I hadn't gotten much further on visualization, but instead started focusing on my first blog post. A bit around that post, ProPublica published some excellent work on parking tickets and ended up releasing its own tickets datasets to the public, one of which was geocoded. I'm happy to say I had a small part in helping out with, and then started using it for my own work in the hopes of using a common dataset between groups.
More Geocoding Fun
A high level of ProPublica's geocoding process is described in pretty good detail here, so if you're interested in how the geocoding was done, you should check that out. In brief, the dataset's addresses were geocoded using Geocodio. The geocoding process they used was dramatically simplified by replacing each address's last two digits with zeroes. It worked surprisingly well, and brought the percent of geocoded tickets to 99%, but this method had the unfortunate side effect of reducing mapping accuracy.
So, because I have more opinions than I care to admit about geocoding, I had to look into how well the geocoding was done.
Geocoding Strangeness
After a few checks against the geocoded results, I noticed that a large portion of of the addresses wasn't geocoded correctly - often in strange ways.
One example comes from the tendency of geocoders to favor one direction over the other for some streets. As can be seen below, the geocoding done on Michigan and Wells is completely demolished. What’s particularly notable here is that Michigan Ave has zero instances of “S Michigan” swapped to “N Michigan”.
| N Wells | S Wells | Total | |
|---|---|---|---|
| Total Tickets (pre-geocoding) | 280,160 | 127,064 | 407,224 |
| Unique Addresses (pre-geocoding) | 3,254 | 3,190 | 6,444 |
| Total Tickets (post-geocoding) | 342,020 | 37,611 | 379,631 |
| Unique Addresses (post-geocoding) | 40 | 57 | 97 |
| Direction is swapped | 246 | 54,309 | 54,555 |
| N Michigan | S Michigan | Total | |
|---|---|---|---|
| Total Tickets (pre-geocoding) | 102,225 | 392,391 | 494,616 |
| Unique Addresses (pre-geocoding) | 2,916 | 16,585 | 19,501 |
| Total Tickets (post-geocoding) | 15,760 | 509,485 | 512,401 |
| Unique Addresses (post-geocoding) | 136 | 144 | 280 |
| Direction is swapped | 102,225 | 0 | 102,225 |
Interestingly, the total ticket count for Wells drops by about 30k after being geocoding. This turned out to be from Geocodio strangely renaming ‘200 S Wells’ to ‘200 W Hill St’. Similar also happens with numbered addresses similar to “83rd St”, where a steet name is often renamed to "100th". 100th street's ticket count appears to have six times as many tickets as it actually does because of this.
These are just a few examples, but it's probably safe to say it's tip of the iceberg. My gut tells me that the address simplification had a major effect here. I think a simple solution of replacing the last two digits with 01 if odd, and 02 if even - instead of 0s - would do the trick.
Quick Geocoding Story
A few years ago, I approached the (ex) Chicago Chief of Open Data and asked if he, or someone in Chicago, was interested in a copy of geocoded addresses I’d worked on, since they don’t actually have anything geocoded (heh). He politely declined, and mentioned that since Chicago has its own geocoder, my geocoded addresses weren’t useful. I then asked if Chicago could run the parking ticket addresses through their geocoder – something that would then be requestable through FOIA. His response was, “No, because that would require a for loop”.
Hmmmmm.
Visualization to Validate Geocoding
In one of my stranger attempts to validate the geocoding results, I wanted to see whether it was possible to use the distance a ticketer traveled to check if a particular geocode was botched or not. It ended up being less useful I'd hoped, but out of it, I made some pretty interesting looking visualizations:

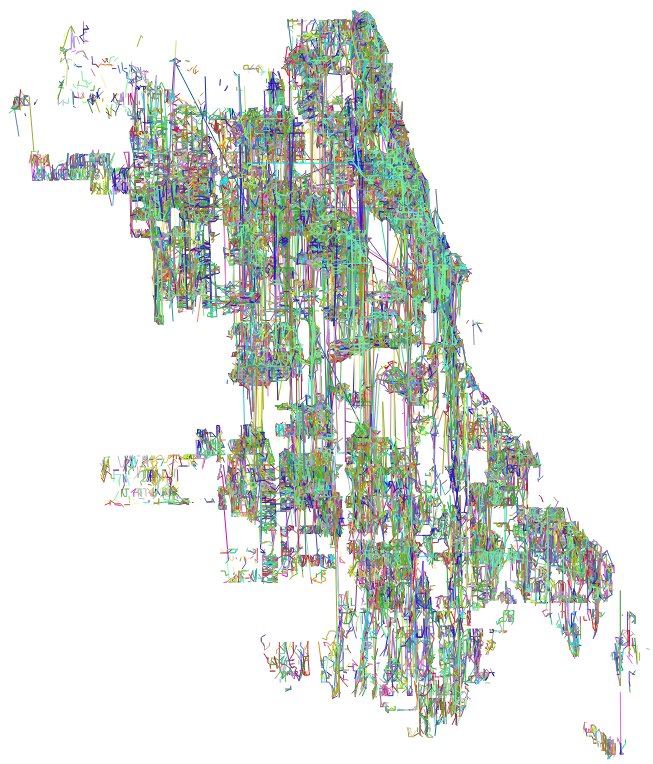
Left: Ticketer paths every 15 minutes with 24 hours decay (Animated). Right: All ticketer paths for a full month.
This validation code, while it wasn't even remotely useful, ended up being the foundation for what I'm calling my final personal attempt to visualize Chicago's parking tickets.
Final Version
And with that, here is the final version of the parking ticket visualization app. Click the image below to navigate to the app.
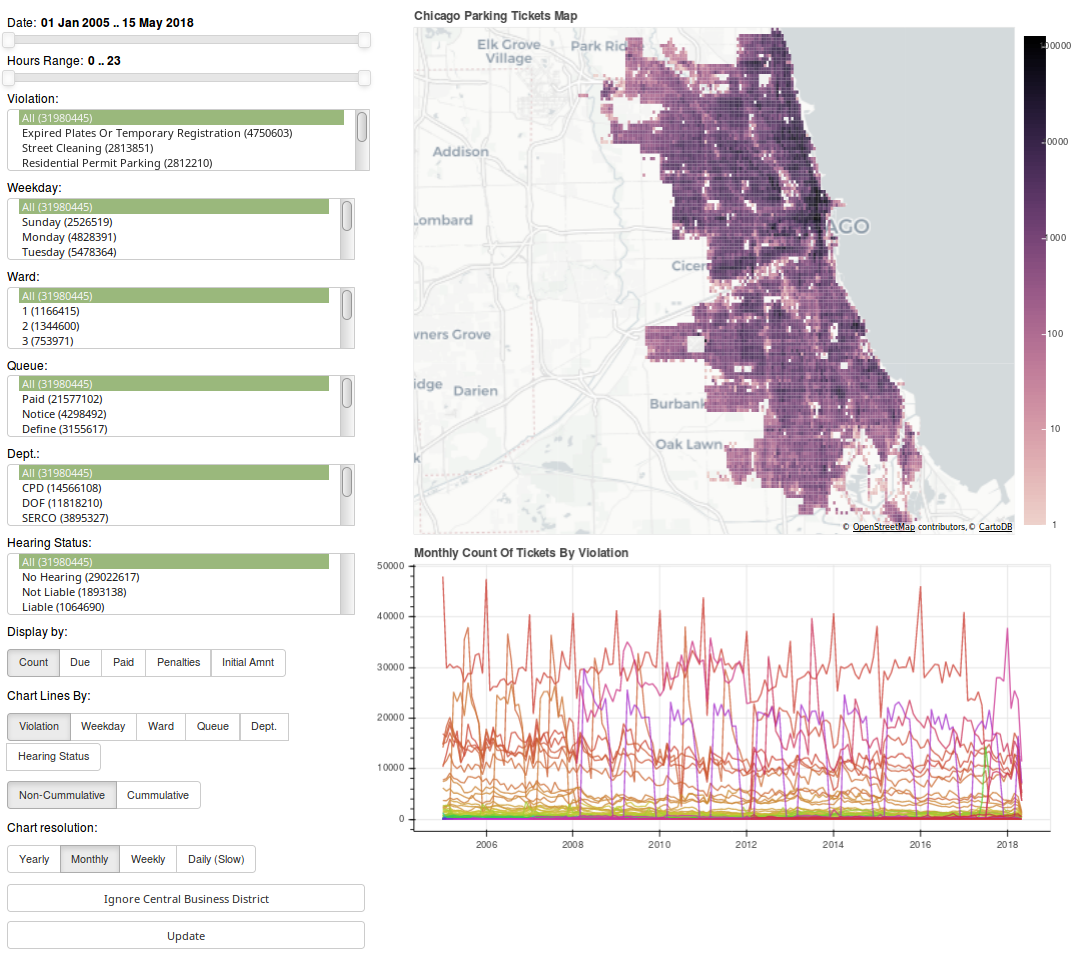
Bokeh Frontend
The frontend for the app uses a python framework named Bokeh. It's an extremely powerful interactive visualization framework that dramatically reduces how much code it takes to make both simple and complex interfaces. It's not without its (many) faults, but in python land, I personally consider it to be the best available. That said, I wish the Bokeh devs would invest a lot more time improving the serverside documentation. There's just way too much guesswork, buggy behavior, and special one-offs required to match Bokeh's non-server functionality.
Flask/Pandas Backend
The original backend was PostgreSQL along with PostGIS (for GeoJSON creation) and TimeScaleDB (for timeseries charting). Sadly, PostgreSQL started struggling with larger queries, combined with memory exhausting itself quicker than I'd hoped. In the end, I ended up writing a Flask service that runs in PyPy with Pandas as an in-memory data store. This ended up working surprisingly well in both speed and modularity. That said, there’s still a lot more room for speed improvement - especially in caching!
If I ever revisit the backend, I'll try giving PostgreSQL another chance, but throw a bunch more optimization its way.
Please feel free to check out the application code.
Interesting Findings
To wrap this post up, I wanted to share some of the things I've found while playing around with the app. Everything below comes from screenshots from the app, so pardon any loss of information.
Snow Route Tickets Outside 3AM-7AM
If you park your car in a "snow route" between 3AM-7AM, you will get a ticket. Interestingly, between the hours of 8am to 11pm, over 1,000 tickets have been given over the past 15 years - mostly by CPD. Of these, only 6% have been contested – 6 of which the car owner was still liable for some reason. The other 94% should have automatically been thrown out, but Chicago has no systematic way of doing this. Shame.
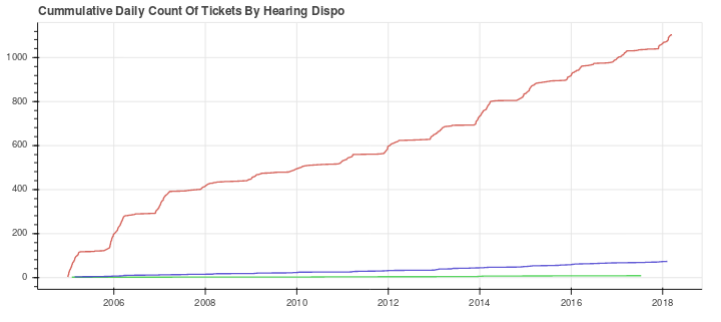
Highest value line = CPD's tickets.
Expired Meter Within Central Business District – Outside of CBD.
Downtown Chicago has an area that's officially described as the “Central Business District”. Within this area, tickets for expired meters end up costing $65 instead of the normal $50. In the past 13 years, over 52k of these tickets have been given outside of the Central Business District. From those 52k, only 5k tickets were taken to court, and 70% were thrown out. Overall, Chicago made around $725k off the $15 difference. Another instance of where Chicago could have systematically thrown out many tickets, but didn't.
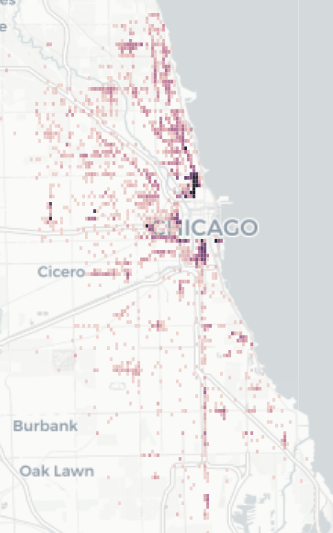
Downtown removed to highlight non-central business district areas.
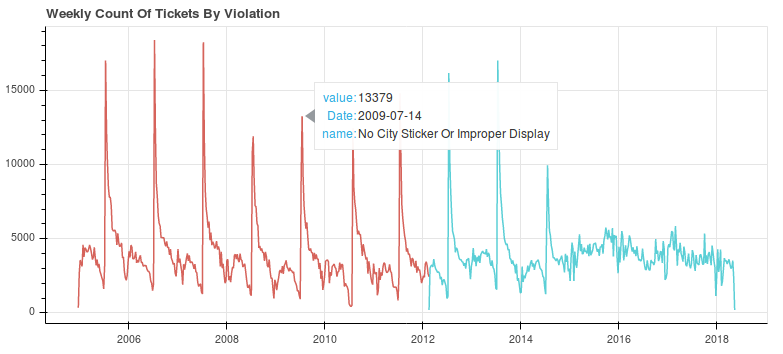
City sticker expiration tickets.. in the middle of July?
Up until 2015, Chicago's city stickers expired at the end of June. A massive spike of tickets is bound to happen, but what's strange is that the spike happens in the middle of July, not the start of it. At the onset of each spikes, Chicago is making somewhere between $500k and $1m. This is a $200 ticket that has a nonstop effect on Chicago's poorer citizens. For more on this, check out this great ProPublica article.
(The two different colors here come from the fact that Chicago changed the ticket description sometime in 2012.)
Bike Lane Tickets
With the increasing prevalence of bike lanes and the danger from cars parked in them, I was expecting to see a lot of tickets for parking in a bike lane. Unfortunately, that’s not the case. For example, in 2017, only around 3,000 tickets for parking in a bike lane were given. For more on this, click here.
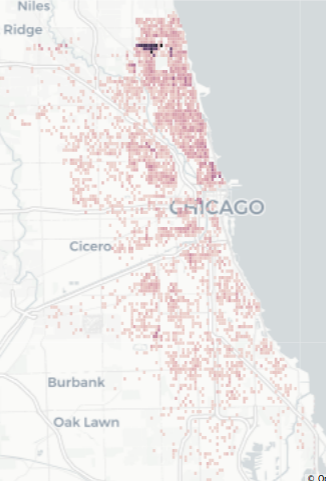
Wards Have different Street Cleaning times
I found some oddities while searching for street cleaning tickets given at odd hours. Wards 48, 49 and 50 seem to give out parking tickets much later than the rest of Chicago. Then, starting at 6am, Ward 40 starts giving out tickets earlier than the rest of Chicago. Posted signs probably make it relatively clear that there’s going to be street cleaning, but it’s also probably fair to say that this is understandably confusing. Hopefully there’s a good reason these wards decided to be special.
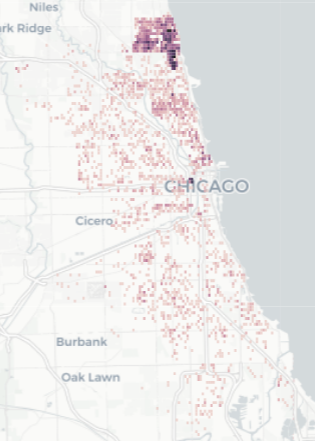
What’s Next?
That's hard to say. There's a ton of work that needs to be done to address the systemic problems with Chicago's parking, but there just aren't enough people working on the problem. If you're interested in helping out, you should definitely download the data and start playing around with it! Also, if you're in Chicago, you should also check out ChiHackNight on Tuesday nights. Just make sure to poke some of us parking ticket nerds beforehand in #tickets on CHiHackNight's slack.
That said, a lot of these issues should really be looked at by Chicago in more depth. The system used to manage parking ticket information - CANVAS - has cost Chicago around $200,000,000, and yet it's very clear that nobody from Chicago is interested in diving into the data. In fact, based on an old FOIA request, Chicago has only done a single spreadsheet's worth of analysis with its parking ticket data. I hope that some day Chicago starts automating some ticket validation workflows, but it will probably take a lot of public advocacy to compel them to do so.
Unrelated Notes
Recently I filed suit against Chicago after a FOIA request for the columns and table names of CANVAS was was rejected with a network security exemption. If successful, I hope that the information can be used to submit future FOIA requests using the database schema as the foundation. I'm extremely happy with the argument I made, and I plan on writing about it as the case comes to a close.
Anywho, if you like this post and want to see more like it, please consider donating to my non-profit, Free Our Info, NFP which recently became a 501(c)(3). Much of the FOIA work from this blog (much of which is unwritten) is being filtered over to the NFP, so donations will allow similar work to continue. A majority of the proceedings will go directly into paying for FOIA litigation. So, the more donations I receive, the more I can hold government agencies accountable!
Hope you enjoyed.
Tags: tickets, foia, chicago, bokeh, visualization
That Time the City of Seattle Accidentally Gave Me 32m Emails for 40 Dollars
Background
In my last post, I wrote about my adventure of requesting metadata for both phone calls and emails from the City of Chicago Office of the Mayor. The work there - and its associated frustration - sent me down a path of sending requests throughout the US to both learn whether these sorts of problems are systemic (megaspoiler: they are) and to also start mapping communication across the United States. Since then, I’ve submitted over a hundred requests for email metadata across the United States – at least two per state.
The first large batch of requests for email metadata were sent to the largest cities of fourteen arbitrary states in a trial run of sorts. In the end of that batch, only two cities were willing to continue with the request - Houston and Seattle. Houston complied surprisingly quickly and snail mailed the metadata for 6m emails.
Seattle on the other hand...
The Request
On April 2, 2017 I sent this fairly boilerplate request to Seattle's IT department:
For all emails sent to/from any Seattle owned email address in 2017, please provide the following information:
1. From address
2. To address
3. bcc addresses
4. cc addresses
5. Time
6. Date
Technically this request can done with a single line powershell command. At a policy level, though, it usually gets a lot of pushback. Seattle's first response included a bit of gobsmackery that I’ve almost become used to:
Based on my preliminary research, there have been 5.5 million emails sent and 26.8 million emails received by seattle.gov email addresses in the past 90 days. This is a significant amount of records that will need to be reviewed prior to sharing them with you. Do you have a more targeted list of email addresses you might be interested in? If not, I will work to find out how long review will take and will be in touch.
Of course, I still want the records, so -
I would like to stick with this request as-is for all ~32m emails. Since this request is for metadata only, the amount of review needed should be relatively small.
Fee Estimate of 33 Million Dollars

A week later, I received this glorious response. Each paragraph is interesting in itself, so let’s break most of it down piece by piece.
Rewording of request
This acknowledges receipt of your public disclosure request C012032-041017 received on April 03, 2017 regarding:
All emails sent to/from any Seattle owned email address in 2017 including metadata:1. From address2. To address3. bcc addresses4. cc addresses5. Time6. Date
Notice the change of language from the original wording. Their rewording completely changes the scope of the request so that it's not just for metadata, but also the emails contents. No idea why they did that.
Salary Fees
With that being said, Seattle IT estimates spending 30 seconds to two minutes to review each email. It has been estimated that this work will take approximately 320 years of staff time at an expense of $33 million in salary.
Wot.
Normally, a flustered public records officer would just reject a giant request for being for “unduly burdensome”… but this sort of estimate is practically unheard of. So much so that other FOIA nerds have told me that this is the second biggest request they've ever seen. The passive aggression is thick. Needless to say, it's not something I'm willing to pay for!
The estimate of 30s per metadata entry is also a bit suspect. Especially with the use of Excel, which would be useful for removing duplicates, etc.
Storage Fees
We estimate that this request contains 8-10 terabytes of information, for which we could need to stand up an FTP server through which the requester will be able to download cleared email meta data. As allowed under RCW 42.56.120, we would charge the requester for the actual copying costs of fulfilling this request. Based on the Seattle IT cost model used for internal City charge backs, the anticipated cost to the requester is $2,480 per year plus $2.11 per gigabyte of storage. We are still working on the storage requirements for this effort. If we assume 10 TB of storage, this would require $21,606.40/year in requester fees.
Heh. Any sysadmin can tell you that The costs of storage doesn’t exactly come from the storage medium itself; administration costs, supporting hardware, etc, are the bulk of the costs. But come on, let’s be realistic here. There’s very little room for good faith in their cost estimates – especially since the last time a single gigabyte cost that much was between 2002 and 2004.
That said – some other interesting things going on here:
- Their file size estimation is huge. For comparison, that Houston’s email metadata dump was only 1.2GB.
- The fact that they mention “meta data” [sic] implies that they did acknowledge that the request was for metadata.
- Seattle already uses Amazon S3 to store public records requests’ data. At the time, S3 was charging $.023/GB
Continue anyway?
At this time, the City anticipates that it will be able to provide a first installment of records on or about May 29, 2017. However, please note that this time estimate may change depending on the clarification you provide and as we continue to process your request. If the City does not hear from you within 30 days, the City will consider your request closed.
Oddly, they don't actually close out the request and instead ask whether I wanted to continue or not. I responded to their amazing email by asking how many records I'd receive on May 29th, but never received an answer back.
Reversal of the Original Cost Estimate
On June 5, they sent a new response admitting that their initial fee estimation was wrong, and asked for $1.25 for two days’ (out of three months) of records:
At this point I can send you an exel spreadsheet with the data points you are requesting. The cost for the first installment is $1.25 for emails sent or received on January 1 and 2, 2017. Because the spreadsheet does not contain the body of the email and just the metadata that you requested, no review will be necessary, and we'll be able to get this information to you at a faster pace than the 320 years quoted you earlier.
Because they're asking for a single check for $1.25 for just two days’ worth of metadata – and wouldn’t send anything until that first check came in, my interpretation is that they’re taking a page from /r/maliciouscompliance and just making this request as painful as possible just for the simple sake of making it difficult. So in response, I preemptively sent them fourteen separate checks. The first thirteen checks were all around ~$1.25. That seemed to work, since they never asked for a single payment afterwards.
From there, my inbox went mostly silent for two months, and I mostly forgot about the request, though they eventually cashed all of the checks and made me an account for their public records portal.
SNAFU
Fast forward to August 22, when I randomly added that email account back to my phone. Unexpectedly, it turned out they actually finished the request! And without a bill for millions of dollars! Sure enough, their public records request portal had about 400 files available to download, which all in all contained metadata for about 32 million emails. Neat!
Problem though... they accidentally included the first 256 characters of all 32 million emails.
Here are some things I found in the emails:
- Usernames and passwords.
- Credit card numbers.
- Social security numbers and drivers licenses.
- Ongoing police investigations and arrest reports.
- Texts of cheating husbands to their lovers.
- FBI Investigations.
- Zabbix alerts.
In other words... they just leaked to me a massive dataset filled with intimately private information. In the process, they very likely broke many laws, including the Privacy Act of 1974 and many of WA's own public records laws. Frankly, I'm still at a loss of words.
It’s hard to say how any of this happened exactly, but odds are that a combination of request’s rewording and the original public records officer going on vacation led to a communication breakdown. I don’t want to dwell on the mistake itself, so I’ll stop it at that.
Side note to Seattle's IT department - clean up your disks. You shouldn't have that many disks at 100%!
Raising the Issue
I responded as passively as possible in the hopes that they’d catch their mistake on their own:
The responsive records are not consistent with my request and includes much more info than I initially requested. Could you please revisit this request and provide the records responsive to my initial request?
Their response:
The information that you requestedis located in columns:
From address = column J
To address = column K
bcc address = column M
cc address = column L
Time and date = column R of the reports.
The records were generatedfrom a system report and I am unable to limit the report to generate only thefields you requested. The City has no duty to create a record that doesnot exist. As such, we have provided all records responsive to yourrequest and consider your request closed.
Disregarding the fact that they used a very common tactic of denying information on the basis that its disclosure would require the creation of new records… they didn’t get the point. I explained what information they leaked, and made it very clear how I was going to escalate this:
Please address this matter as if it was a large data breach. For now, I will be raising this matter to the WA Office of Privacy and Data Protection. None of the files provided to me have been shared with anyone else, nor do I have any future intention of sharing.
Their response:
Thank you for your email and bringing this inadvertent error to our attention so quickly. We have temporarily suspended access to GovQA while we look into the cause of this issue. We are also working on reprocessing your request and anticipate providing you with corrected copies of the records you requested through GovQA next week. In the meantime, please do not review, share, copy or otherwise use these records for any purpose.
We are sorry for any inconvenience.
Phone Call
Not too long after that, after contacting some folks on Seattle’s Open Data Slack, I found my way onto a conference phone call with both Seattle’s Chief Technology officer and their Chief Privacy Officer and we discussed what happened, and what should happen with the records. They thanked me for bringing the situation to their attention and all that, but the mood of the call was as if both parties had a knife behind their back. Somewhere towards the end of the call, I asked them if it was okay to keep the emails. Why not at least ask, right?
Funny enough, in the middle of that question, my internet died and interrupted the call for the first time in the six months I lived in that house. Odd. It came back ten minutes later, and I dialed back into the conference line, but the mood of the call pretty much 180’d. They told me:
- All files were to be deleted.
- Seattle would hire Kroll to scan my hard drives to prove deletion.
- Agreeing to #1 and #2 would give me full legal indemnification.
This isn't something I'm even remotely cool with, so we ended the call a couple minutes later, and agreed to have our lawyers speak going forward.
Deleting the Files
After that call, I asked my lawyer to reach out to their lawyer and was pretty much told that Seattle was approaching the problem as if they were pursuing Computer Fraud And Abuse (CFAA) charges. For information that they sent. Jiminey Cricket..
So, I deleted the files.
Most of what happened next over a month or so was mostly between their lawyer and mine, so there’s not really that much for me to say. Early on I suggested that I write an affidavit that explains what happened, how I deleted the files, and I validated that the files were deleted. They mostly agreed, but still wanted to throw some silly assurance things my way – including asking me to run a bash script to overwrite any unused disk space with random bits. I eventually ran zerofree and fstrim instead, and they accepted the affidavit. No more legal threats from there.
Seattle’s Reaction
About a week after the phone call, a Seattle city employee contacted Seattle’s KIRO7 about the incident. In KIRO7's investigation, they learned that, Seattle hadn’t sent any disclosure of the leak - something required by WA’s public records request law. Only after their investigation did Seattle actually notify its employees about the emails leak. Link to their story (video inside).

A week later, another article was published by Seattle’s Crosscut which goes into a lot of detail, including some history of Seattle's IT department. This line towards the bottom still makes me laugh a little:
The buffer against potential legal and administrative chaos in this scenario is only that Chapman has turned out to be, as Armbruster described him, a "good Samaritan." Efforts to track down Chapman were not successful; Crosscut contacted several Matthew Chapmans who denied being the requester.
On January 19th, Seattle's CTO, Michael Mattmiller gave his resignation. Whether his resignation is related to the email leak is hard to say, but I just think the timing makes it worth mentioning.
Finally – The Metadata
Starting January 26th, Seattle started sending installments of the email metadata I requested. So far they've sent 27 million emails. As of the writing of this post, there are only two departments who haven’t provided their email metadata: the Police Department and Human Services.
You can download the raw data here.
Some things about the dataset:
- It’s very messy – triple quotes, semicolons, commas, oh my.
- There are a millions of systems alerts.
- For seattle.gov → seattle.gov communication, there are two distinct metadata records.
In any case, it's still somewhat workable, so I've been working on a proof of concept for its use in the greater context of public records laws. Not ready to talk much about it yet, so here's is a gephi graph of one day's worth of metadata. Its layout is Yifan Hu and filtered with a k-core minimum of 5 and a minimum degree of 5:

Please reach out to me if you'd like to help model these networks.
One Last Thing: Legislative Immunity Kerfuffle
This last section might not be related, but the timing is interesting, so I feel it’s worth mentioning.
On February 23 - between the first installment of email metadata and the second - WA’s legislature attempted to pass SB6617, a bill which removes requirements for disclosure of many of their records – including email exchanges - from WA’s public records laws. What’s particularly interesting about this events of this bill is that it took less than 24 hours from the time it was read for the first time to the time that it passed at both the House and Senate and sent to the Governor’s office.
Seattle Times wrote a good article about it.
Thankfully, after the WA governor’s office received over 6,300 phone calls, 100 letters, and over 12,500 emails, the governor ended up vetoing the bill. Neat.
It's hard to say if that caused any sort of delay, but after a month and a half of waiting:
How are the installments looking? I saw that there was some recent legislative immunity kerfuffle around emails. Is that related to any delays?
And got this response:
Good news. The recent Washington state legislative immunity kerfuffle will not impact your installments. We have fixed the bug that was impacting our progress and are now on our way. In fact, I'll have more records for you this week.
A month later, they started sending the rest.
What’s Next?
The work done throughout this post has led to a massive trove of information that ought to be enormously useful in understanding the dynamics of one the US's biggest cities. A big hope in making this sort of information available to the public is that it will help in changing the dynamic of understanding what sorts of information is accessible.
That said, this is just one city of many which have given me email metadata. As more of it comes through, I’ll be able to map out more and more, but the difficulty in requesting those records continues to get in the way.
Once I get some of these bigger stories out of the way, I’ll start writing fewer stories and write more about public records requesting fundamentals – particularly for digital records.
Next post will be about my ongoing suit against the White House OMB for email metadata from January 2017. This past Wednesday was the first court date - where the defendent's counsel never showed up.
Hope you enjoyed!
Tags: seattle, foia, kerfuffle, metadata
A tale about requesting Chicago’s Mayor’s Office’s phone records.
Intro
Back in 2014, I had the naive goal of finding evidence of collusion between mayoral candidates. The reasoning is longwinded and boring, so I won't go into it. My plan was to find some sort of evidence through a FOIA request or two for the mayor's phone records, find zero evidence of collusion, then move onto a different project like I normally do. What came instead was a painful year and a half struggle to get a single week's worth of phone records from Chicago's Office of the Mayor.
Hope you enjoy and learn something along the way!
Requests to Mayor's Office
My first request was simple and assumed that the mayor's office had a modern phone. On Dec 8, 2014, I sent this anonymous FOIA request to Chicago's Office of the Mayor:
Please attach all of the mayor's phone records from any city-owned phones (including cellular phones) over the past 4 years.
Ten days later, I received a rejection back stating they didn't have any of the mayor's phone records:
A FOIA request must be directed to the department that maintains the records you are seeking.
The Mayor’s Office does not have any documents responsive to your request.
Then, to test testing whether it was just the mayor whose records their office didn't maintain, I sent another request to the Office of the Mayor - this time specifically for the FOIA officer's phone records and got the same response.
Maybe another department has the records?
VoIP Logs Request
An outstanding question I had (and still have, to some extent) is whether or not server logs are accessible through FOIA. So, to kill two birds with one stone, I sent a request for VoIP server logs to Chicago's Department of Innovation and Technology (DoIT):
Please attach in a standard text, compressed format, all VoIP server logs that would contain phone numbers dialed between the dates of 11/24/14 and 12/04/14 for [the mayor's phone].
Ten days later (and five days late), I received a response that my request was being reviewed. Because they were late to respond, IL FOIA says that they can no longer reject my request if it's unduly burdensome - one of the more interesting statutory pieces of IL FOIA.
The phone... records?
A month goes by, and they send back a two page PDF with phone numbers whose last four digits are redacted:

...along with a two and a half page letter explaining why. I really encourage you to read it.
tl;dr of their response and its records:
- They claim that the review/redaction process would be extremely unduly burdensome - even though they were 5 days late!
- The pdf includes 83 separate phone calls, with 45 unique phone numbers.
- The last four digit of each phone number is removed.
- Government issued cell phones’ numbers have been removed completely for privacy reasons.
- Private phone numbers aren’t being redacted to the same extent as government cell phones.
- Government desk phones are redacted.
Their response is particularly strange, because IL FOIA says:
"disclosure of information that bears on the public duties of public employees and officials shall not be considered an invasion of personal privacy."
With the help of my lawyer, I sent an email to Chicago explaining this... and never received a response. Time to appeal!
Request for Review
In many IL FOIA rejections, the following text is written at the bottom:
You have a right of review of this denial by the IL Attorney General's Public Access Counselor, who can be contacted at 500 S. Second St., Springfield, IL 62706 or by telephone at (217)(558)-0486. You may also seek judicial review of a denial under 5 ILCS 140/11 of FOIA.
I went the first route by submitting a Request for Review (RFR). The RFR letter can be boiled down to:
- They stopped responding.
- Redaction favors the government personnel’s privacy over individuals’, despite FOIA statute.
- Their response to the original request took ten days.
Seven Months Later
Turns out RFRs are very, very slow. So - seven months later, I received a RFR closing letter with a non-binding opinion saying that Chicago should send the records I requested. Their reason mostly boils down to Chicago not giving sufficient reason to call the request unduly burdensome.
A long month later - August 11, 2015: - Chicago responds with this, saying that my original request was for VoIP server logs, which Chicago doesn’t have:
[H]e requested "VoIP server logs," which the Department has established it does not possess. As a result, the City respectfully disagrees with your direction to produce records showing telephone numbers, as there is not an outstanding FOIA request for responsive records in the possession of the Department.
Sure enough, his phone is pretty ancient:

Do Over
And so after nine months of what felt like wasted effort, I submitted another request that same day:
Please attach [...] phone numbers dialed between the dates of 11/24/14 and 12/04/14 for [the Office of the Mayor]
Two weeks later - this time with an on-time extension letter - I'm sent another file that looks like this:
The exact same file. They even sent the same rejection reasons!
Lawsuit
On 12/2/2015, Loevy & Loevy filed suit against Chicago’s DoIT. The summary of the complaint is that we disagree with their claim that to review and redact the phone records would be extremely unduly burdensome. My part in this was waiting while my lawyer did all the work. I wasn't really involved in this part, so there's really not much for me to write about.
Lawsuit conclusion
Six months later, on May 11, 2016, the city settled and gave me four pages of phone logs - most of which were still redacted. Some battles, eh?
Interesting bits from the court document:
...DoIT and its counsel became aware that, in its August 24, 2015 response, DoIT had inadvertently misidentified the universe of responsive numbers. DoIT identified approximately 130 additional phone numbers dialed from the phones dialed within Suite 507 of City Hall, bringing the total to 171
...FOIA only compels the production of listed numbers belonging to businesses, governmental agencies and other entities, and only those numbers which are not work-issued cell phones.
...DoIT asserted that compliance with plaintiff request was overly burdensome pursuant to Section 3(g) of FOIA. On those grounds —rather than provide no numbers at all — DoIT redacted the last four digits of all phone numbers provided
...in other words, they "googled" each number to determine whether that number was publically listed, and, if so, to whom it belonged. This resulted in the identification of 57 out of the 137 responsive numbers...
Lawsuit Records
All in all, the phone records contained:
- 171 unique phone log entries: 57 unredacted and 114 redacted.
- 32 unique unredacted phone numbers.
- 44 unique redacted phone numbers.
From there, there really wasn't much to work with. Most of the phone calls were day-to-day calls to places like flower shops, doctors and restaurants.
Still, some numbers are interesting:
- A four-hour hotel: Prestige Club: Aura
- Investigative services: Statewide Investigative Services and Kennealy & O'Callaghanh
- Michael Madigan
Data: Lawsuit Records
Going deeper
With all of that done – a year and a half in total for one request - I wasn’t feeling satisfied and dug deeper. This time, I started approaching it methodically to build a toolchain of sorts. So, to determine whether the same length of time could be requested without another lawsuit:
Please provide me with the to/from telephone numbers, duration, time and date of all calls dialed from 121 N La Salle St #507, Chicago, IL 60602 for the below dates.
April 6-9, 2015
November 23-25, 2015
And sure enough, two weeks later, I received two pdfs with phone records – this time with times, dates, from number and call length! Much faster now! Still, it’s lame that they’re still redacting a lot, and there wasn't anything interesting in these records.
Data: Long Distance, Local
Full year of records
How about for a full year for a small set of previously released phone numbers?
Please provide to me, for the year of 2014, the datetime and dialed-from number for the below numbers from the [Office of the Mayor]
(312) 942-1222 [Statewide Investigative Services]
(505) 747-4912 [Azura Investigations]
(708) 272-6000 [Aura - Prestige Club]
(773) 783-4855 [Kennealy & O'Callaghanh]
(312) 606-9999 [Siam Rice]
(312) 553-5698 [Some guy named Norman Kwong]
Again, success!
Siam Rice: 55 calls!
Statewide Investigative Services: 8 calls
Keannealy & O'Callaghanh: 10 calls
Some guy named Norman Kwong: 3 calls
(Interestingly enough, they didn't give me the prestige club phone numbers. Heh!)
Data: Full year records
Full year of records - City hall
And finally, another request for previously released numbers – across all of city hall in 2014 and 2015:
The phone numbers, names and call times to and from the phone numbers listed below during 2014 and 2015 [within city hall]
(312) 942-1222 [Statewide Investigative Services]
(773) 783-4855 [Kennealy & O'Callaghanh]
(312) 346-4321 [Madigan & Getzendanner]
(773) 581-8000 [Michael Madigan]
(708) 272-6000 [Aura - Prestige Club]
Data: City hall full year
This means that a few methods of retrieving phone records are possible:
- A week's worth of (mostly redacted) records from a high profile office.
- A phone records through an office as big as the City Hall.
- The use of requesting unredacted phone numbers for future requests.
Phone directory woes
Of the 27 distinct Chicago phone numbers found within the last request’s records, only five of them could be resolved to a phone number found in Chicago’s phone directory:
DEAL, AARON J
KLINZMAN, GRANT T
EMANUEL, RAHM
NELSON, ASHLI RENEE
MAGANA, JASMINE M
This is a problem that I haven't solved for yet, but it should be easy enough by requesting a full phone directory from Chicago's DoIT. Anyone up for that challenge? ;)
Emails?
This probably deserves its own blog post, but I wanted tease it a bit, because it leads into other posts.
I sent this request with the presumption that the redaction of emails would take a very long time:
From all emails sent from [the Office of the Mayor] between 11/24/14 and 12/04/14, please provide me to all domain names for all email addresses in the to/cc/bcc. From each email, include the sender's address and sent times.
Two months later, I received a 1,751 page document with full email addresses for to, from cc, and bcc, including the times of 18,860 separate emails to and from the mayor’s office. Neat - it only took about a year and a half to figure out how to parse the damn thing, though....
Interestingly, the mayor's email address isn't in there that often...
Data: Email Metadata
What's next?
This whole process was a complete and total pain. The usefulness of knowing the ongoings of our government - especially at its highest levels - are critical for ensuring that our government is open and honest. It really shouldn't have been this difficult, but it was. The difficulties led me down an interesting path of doing many similar requests - and boy are there stories.
Next post: The time Seattle accidentally sent me 30m emails for ~$30.